AI LLM Request
Overview
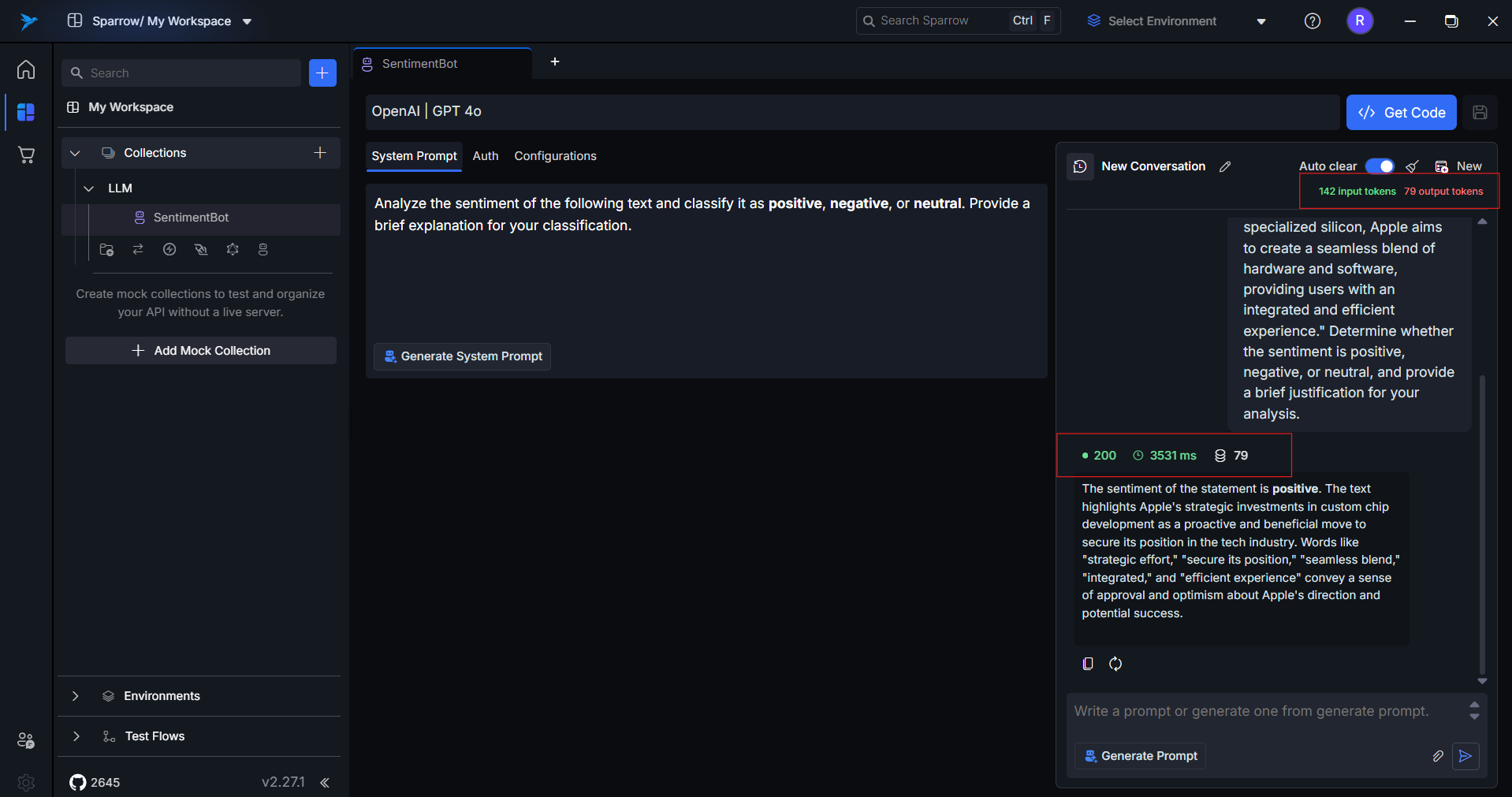
The AI LLM Request feature in Sparrow allows developers to send, test, and manage prompt requests across multiple large language model (LLM) providers like OpenAI, Anthropic (Claude), DeepSeek, and Google Gemini — all from a unified interface. Users can plug in their own API keys, configure request parameters, and interact with different LLMs without switching tools or writing boilerplate code.
Getting Started
-
Navigate to the AI LLM Request tab in Sparrow.
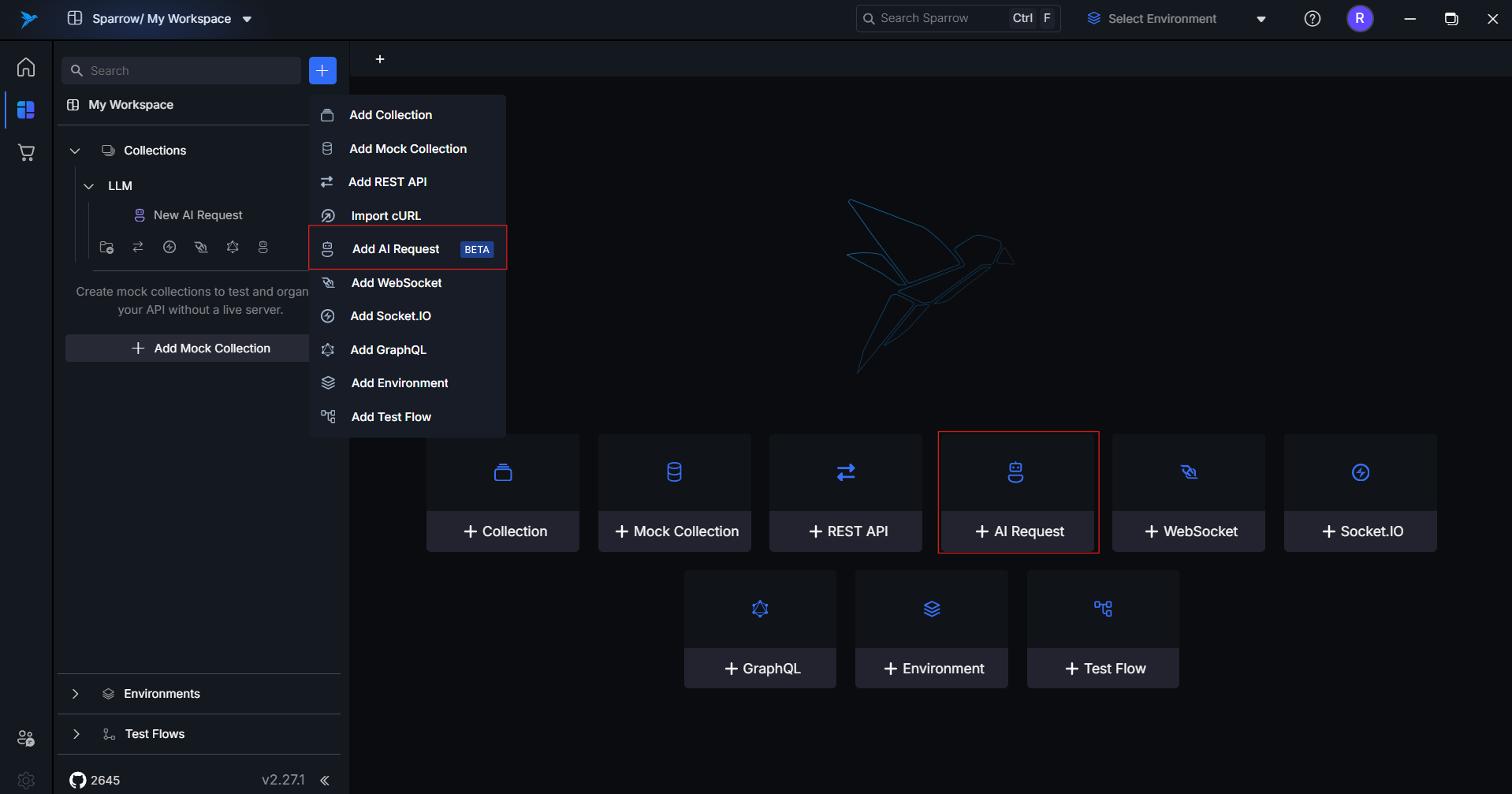
-
Select the LLM provider and model you want to use.
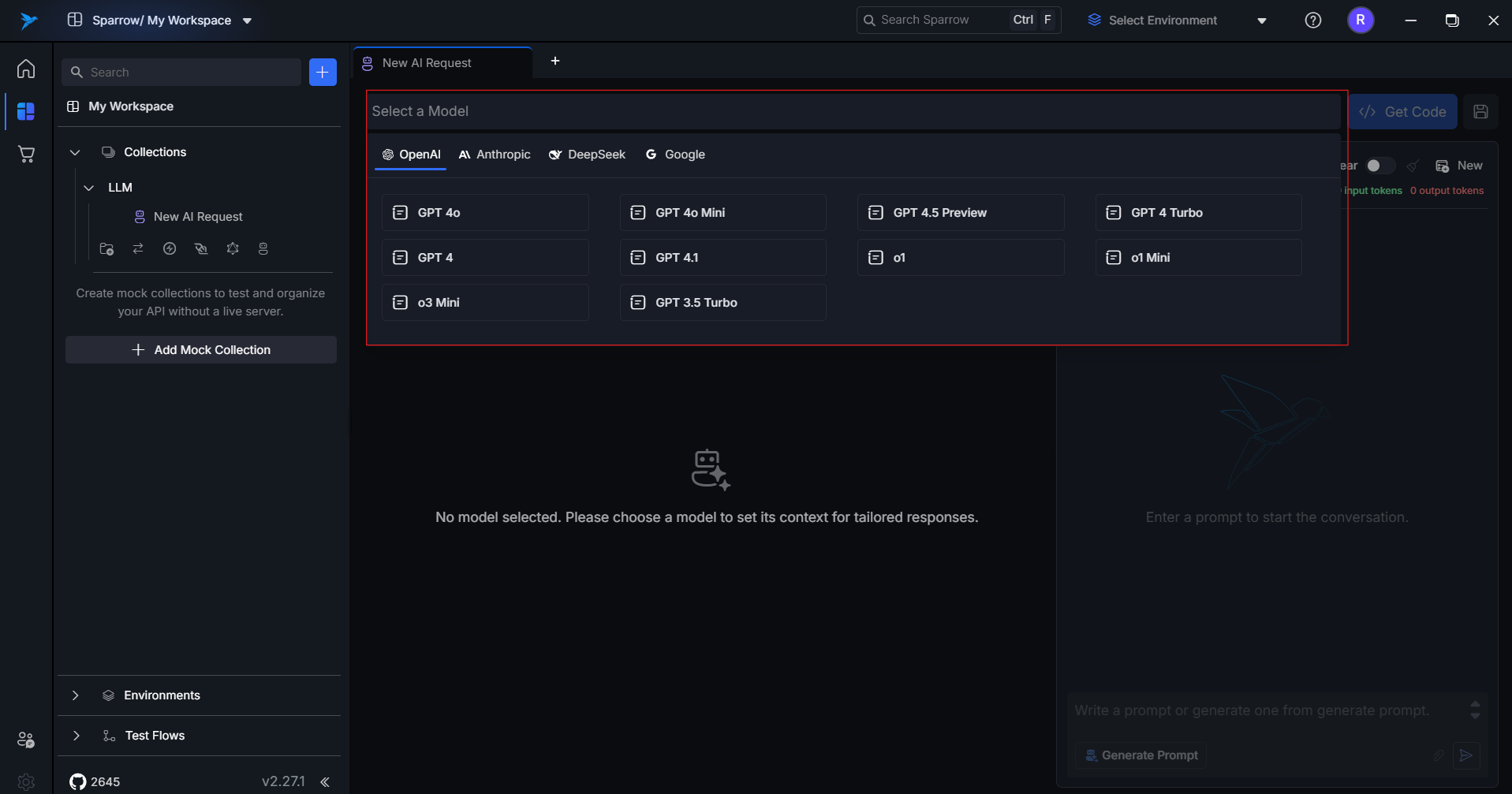
-
Add your API key in the Authentication tab.
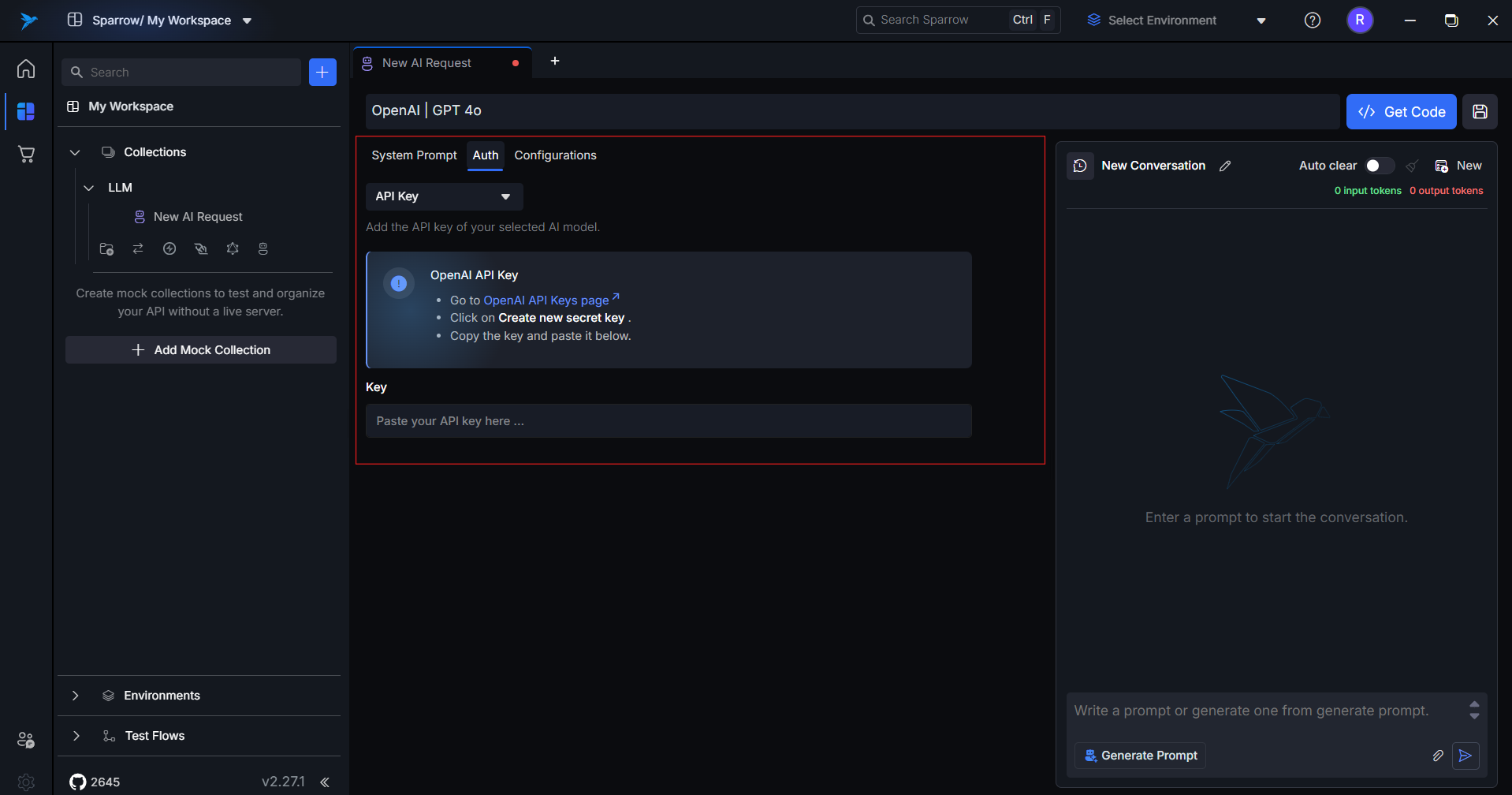
-
Set your desired model configurations in the Configuration tab.
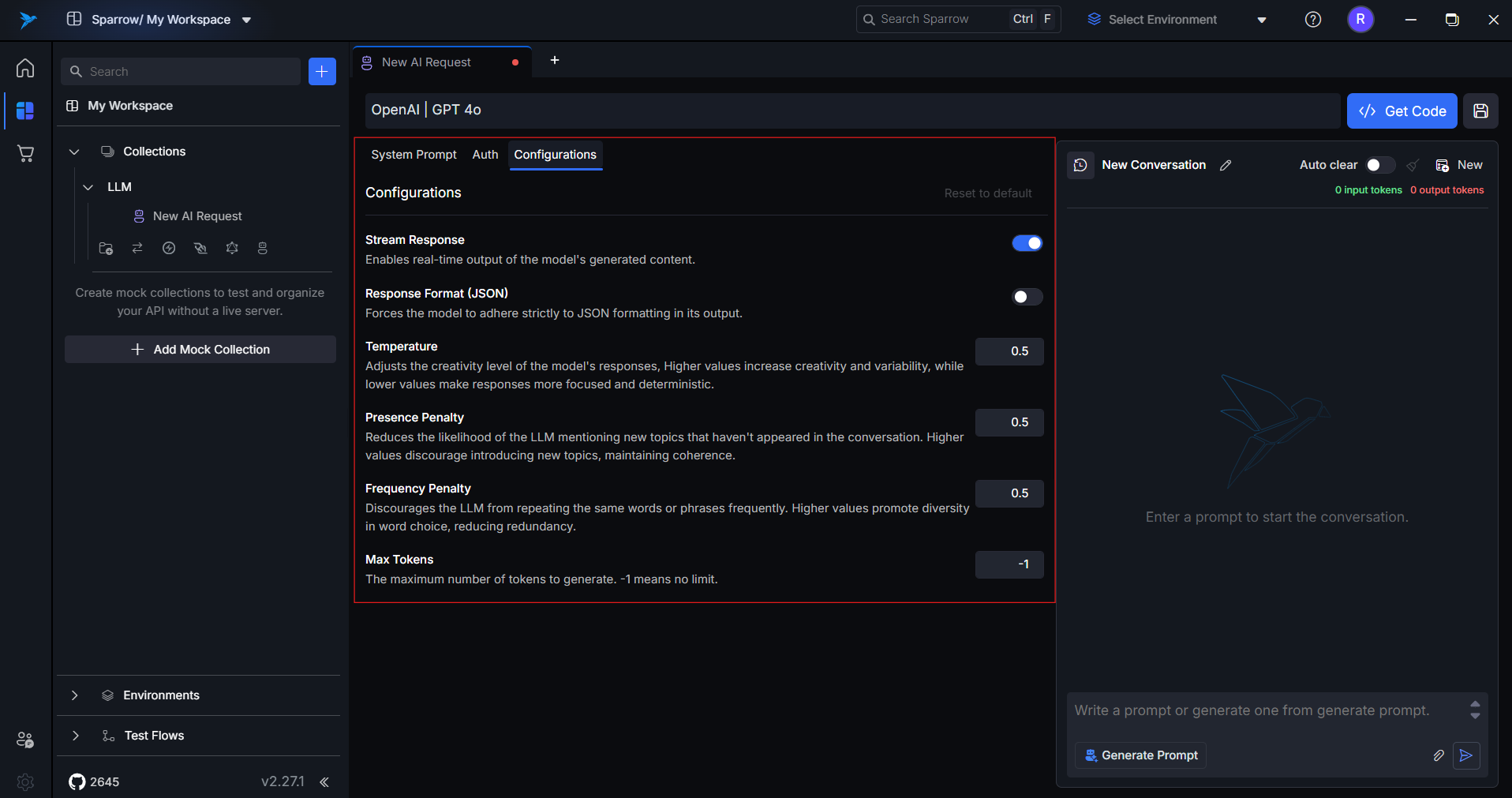
-
Enter prompts manually:
- Use the System Prompt field to define the model's behavior (e.g., tone, role, instructions).
- Use the User Prompt field to enter your actual task or query.
-
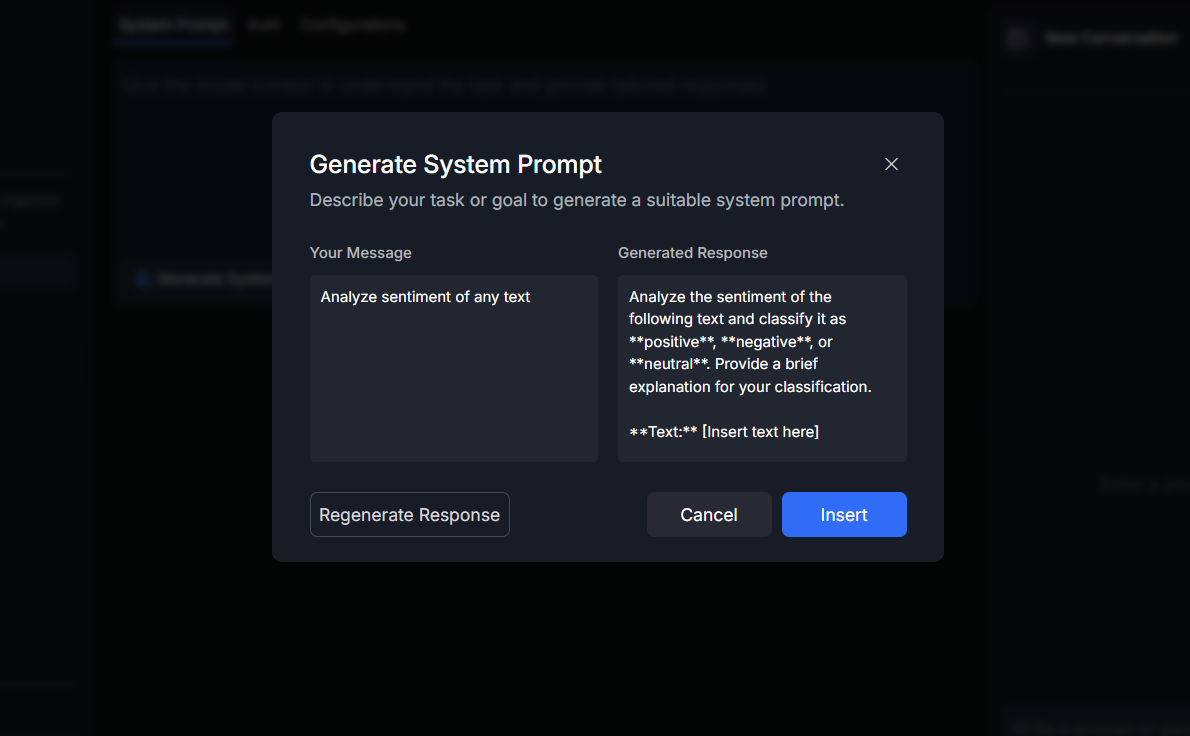
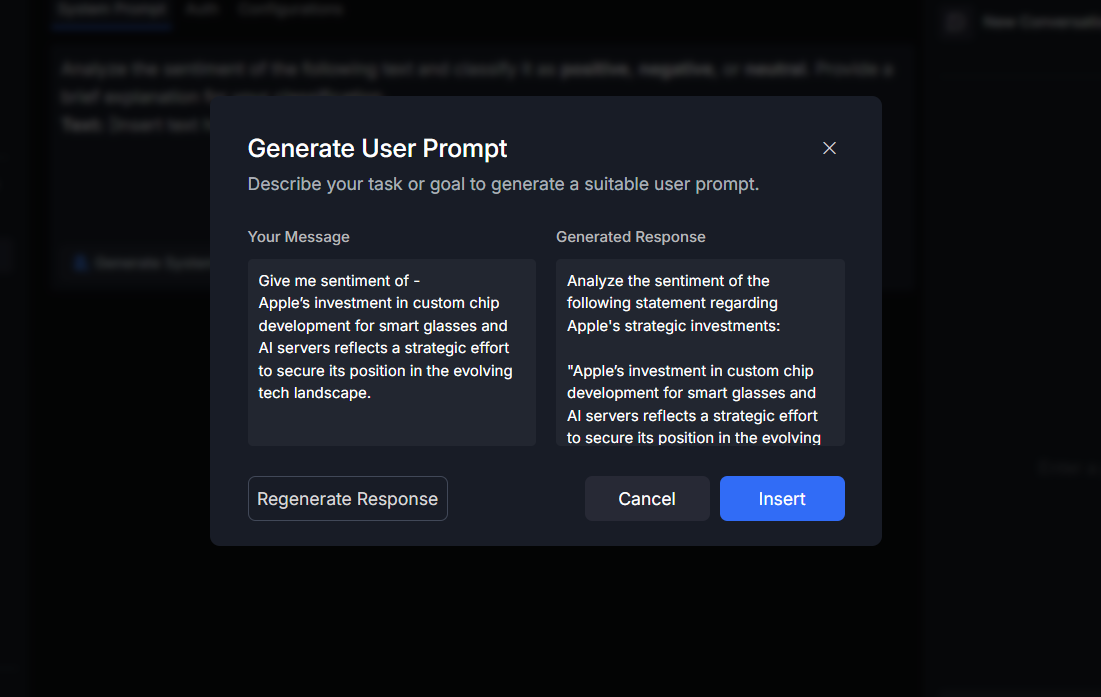
Or generate prompts using Sparrow AI:
- Click the "Generate Prompt" option.
- Describe your use case or requirement in natural language (e.g., "Analyze Sentiment of any text").
- Sparrow AI will generate both the System and User prompts based on your input.
- Use Insert button to Insert the generated prompt in respective sections.
- Use Regenerate Response button to regenerate the prompts.
- Use Cancel to close the prompt window.
-
Click Send to execute the request.
-
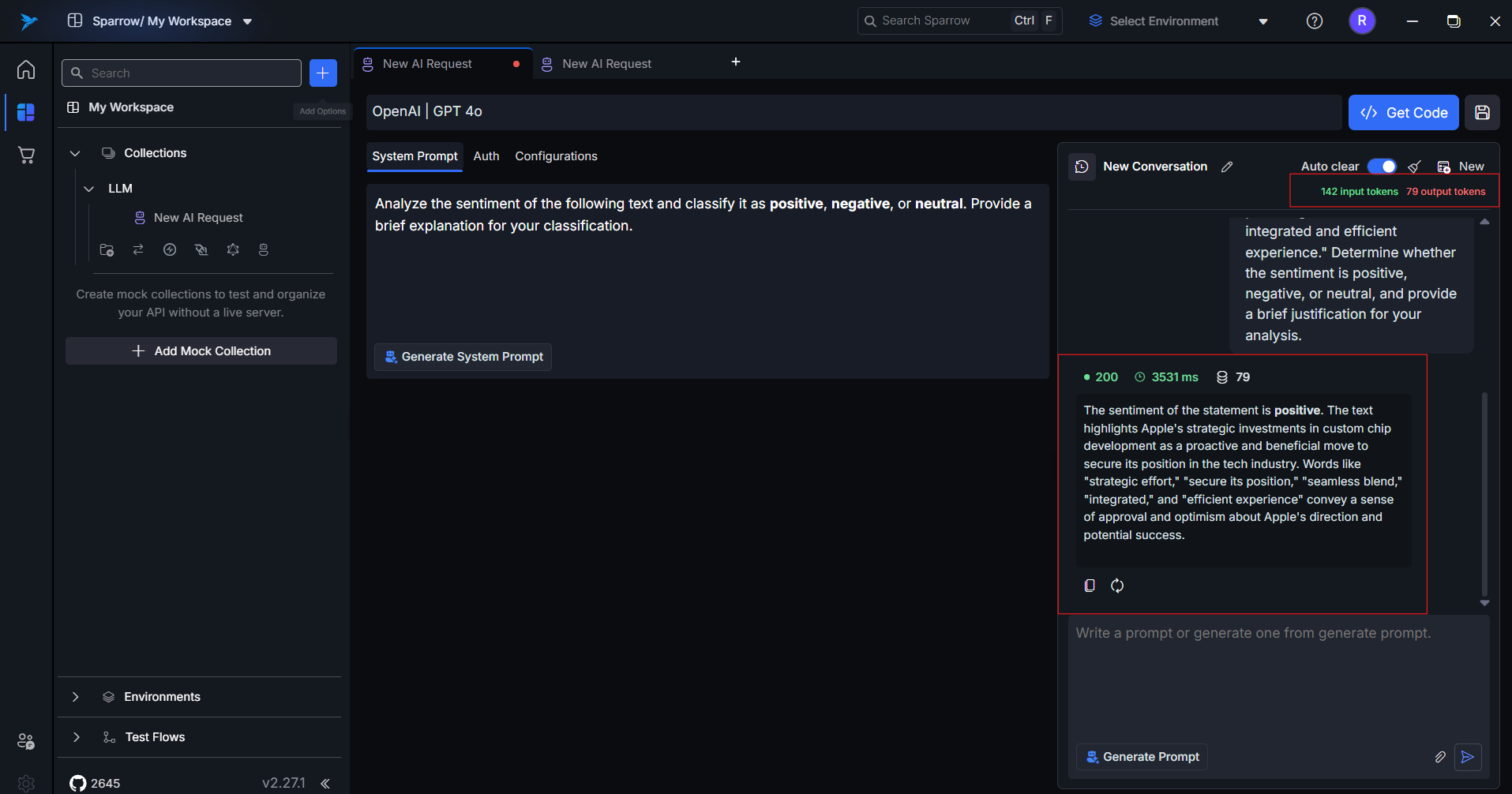
View the response, token counts, and response time.
Feature Breakdown
1. System Prompt and User Prompt
-
System Prompt: Sets the behavior or tone of the model. Example:
"You are a senior software engineer helping junior developers." -
User Prompt: The main query or instruction. Example:
"Explain the difference between async and sync calls in Python."
Useful for prompt tuning and consistent model behavior.
2. Multi-Modality Support (File Upload)
If the selected model supports it, you can upload:
- PDFs
- Text files
These files are passed as part of the request payload. The file upload button is enabled only for models that support it. Maximum 5 files with size 5 MBs allowed.
3. Auto Clear (Context Toggle)
Controls how the model handles conversation history:
- Auto Clear ON: Each prompt is stateless — no memory of past messages.
- Auto Clear OFF: Prompts are part of a conversational thread — model remembers previous messages.
Use case tips:
- Use ON for zero-shot tasks.
- Use OFF for multi-turn Q&A or instruction following.
4. Conversation Rename
Conversations can be renamed inline. This helps in organizing and re-identifying experiments or tests later.
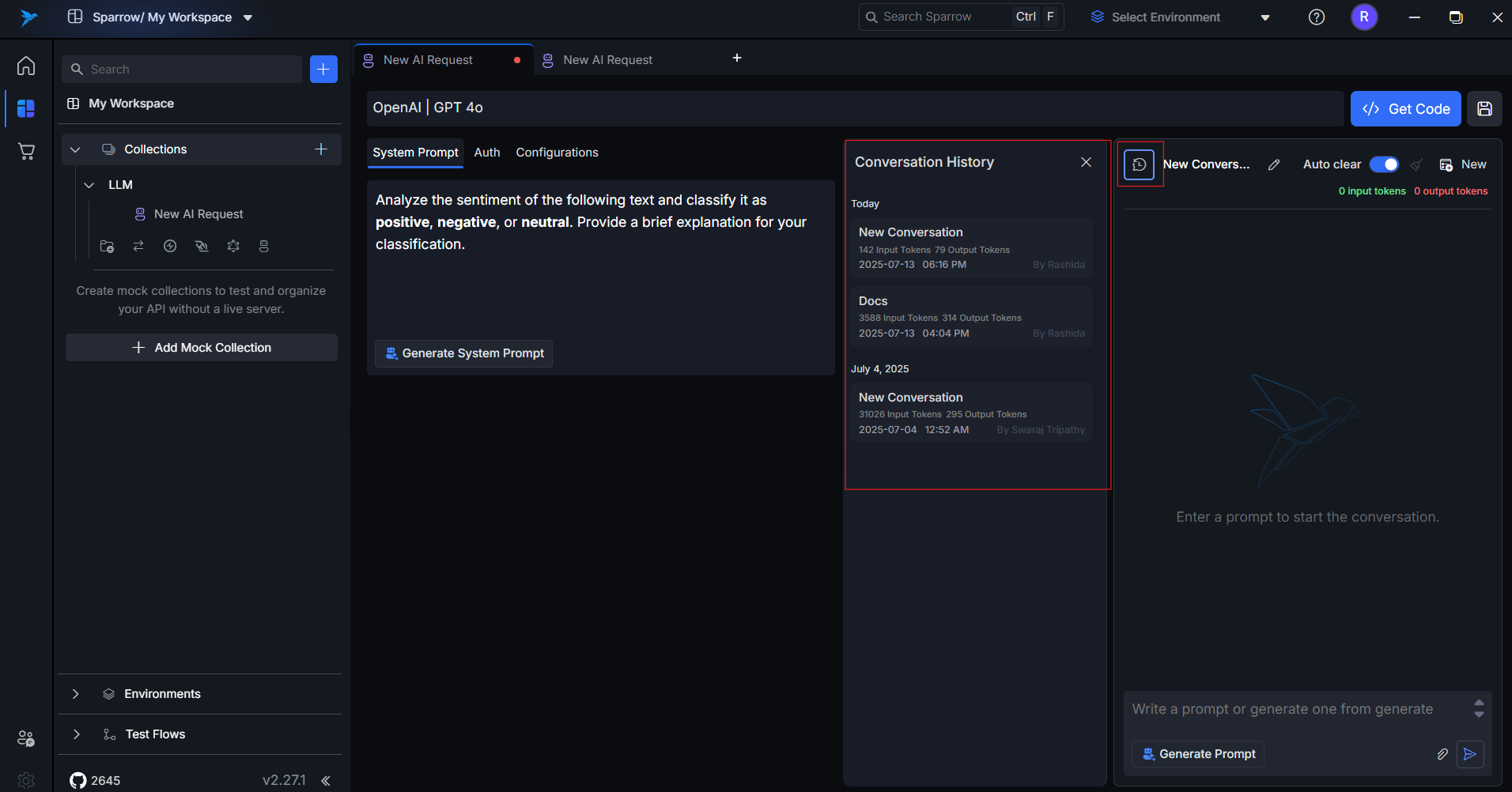
5. Conversation History
All requests and responses are stored automatically unless deleted. You can:
- Reopen any past conversation
- Resume a thread
- Compare previous outputs from different providers
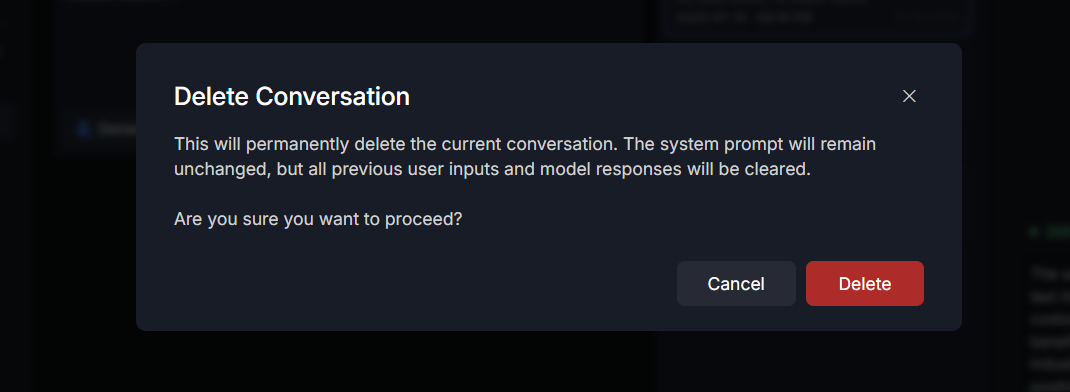
6. Delete Conversation
Removes a selected conversation from history. This is a permanent action.
7. Authentication Tab
Input your API keys for the following providers:
- OpenAI (
sk-...) - Anthropic (
claude-...) - DeepSeek
- Google Gemini
You can add, edit, or remove keys any time. Requests won't work unless the correct key is added.
Note: Sparrow does not store your keys permanently unless you choose to save them.
8. Configuration Tab
This section lets you tweak how the model behaves. Options include:
stream_response: Whether to stream tokens in real-time (if supported).response_format: Choose betweentextorjson.temperature: Controls randomness. (0 = deterministic, 1 = creative)presence_penalty: Penalizes repeated topics.max_tokens: Maximum number of tokens to be generated in the response.
These configs are model-specific and should be tuned based on your use case.
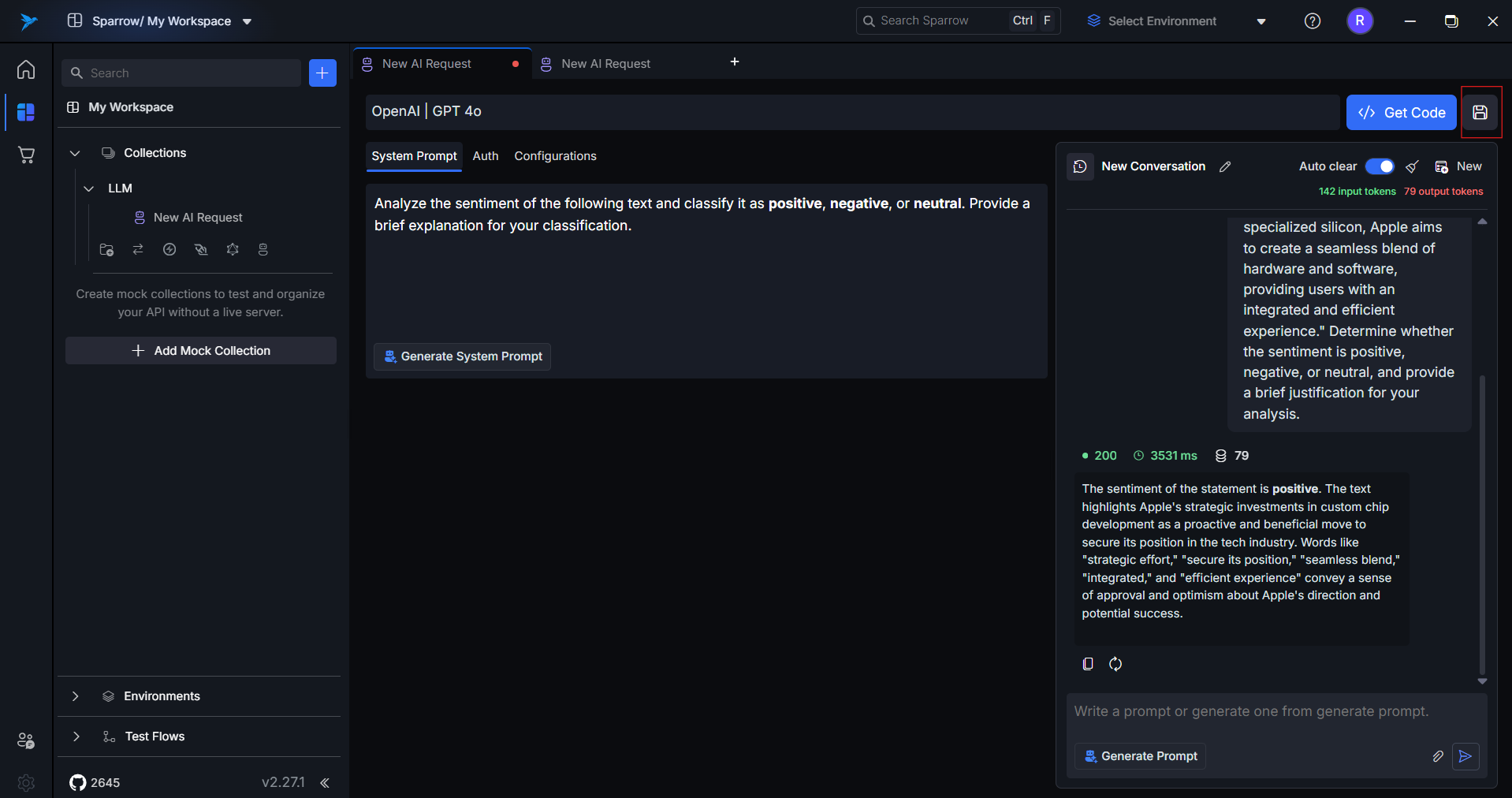
9. Save Conversation to Collection
Allows you to save any conversation to a custom-named collection.
- Saved items are visible in the sidebar under the collection name.
- Helps in organizing by use case (e.g.,
FinancialPrompts,CodeFixes,ClaudeTests).
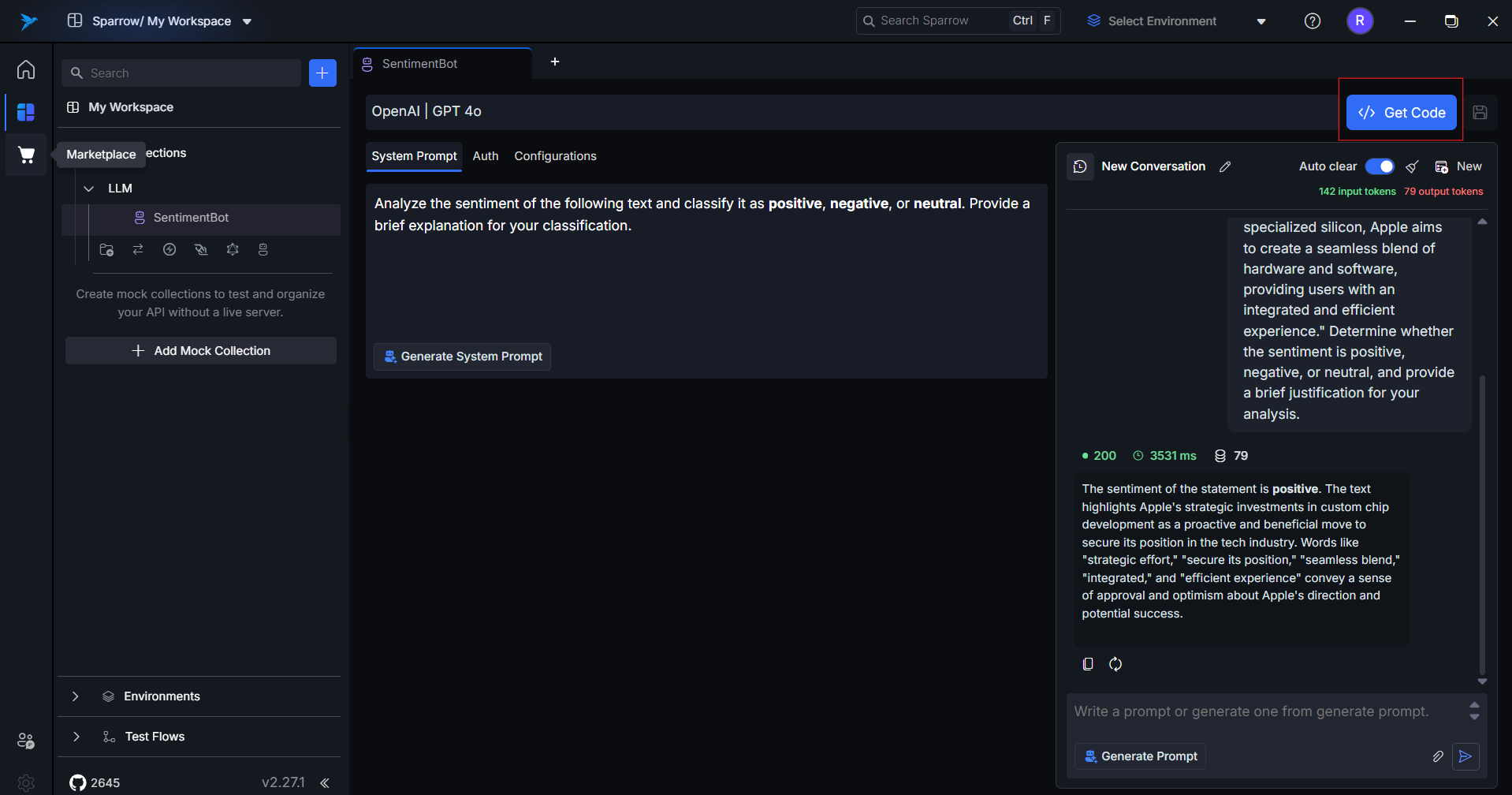
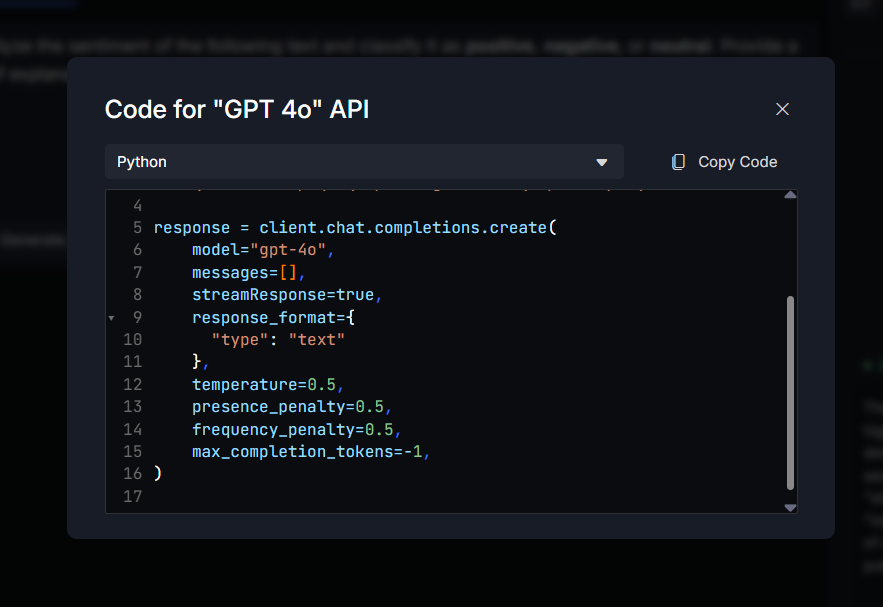
10. Get Code (Python / Node.js)
Automatically generates implementation code for the current request.
- Languages supported:
Python,Node.js - Includes:
- Config
- Headers
- Payload
- Fetch logic
Useful for:
- Rapid prototyping
- Transitioning from UI to code
- Sharing with dev teams
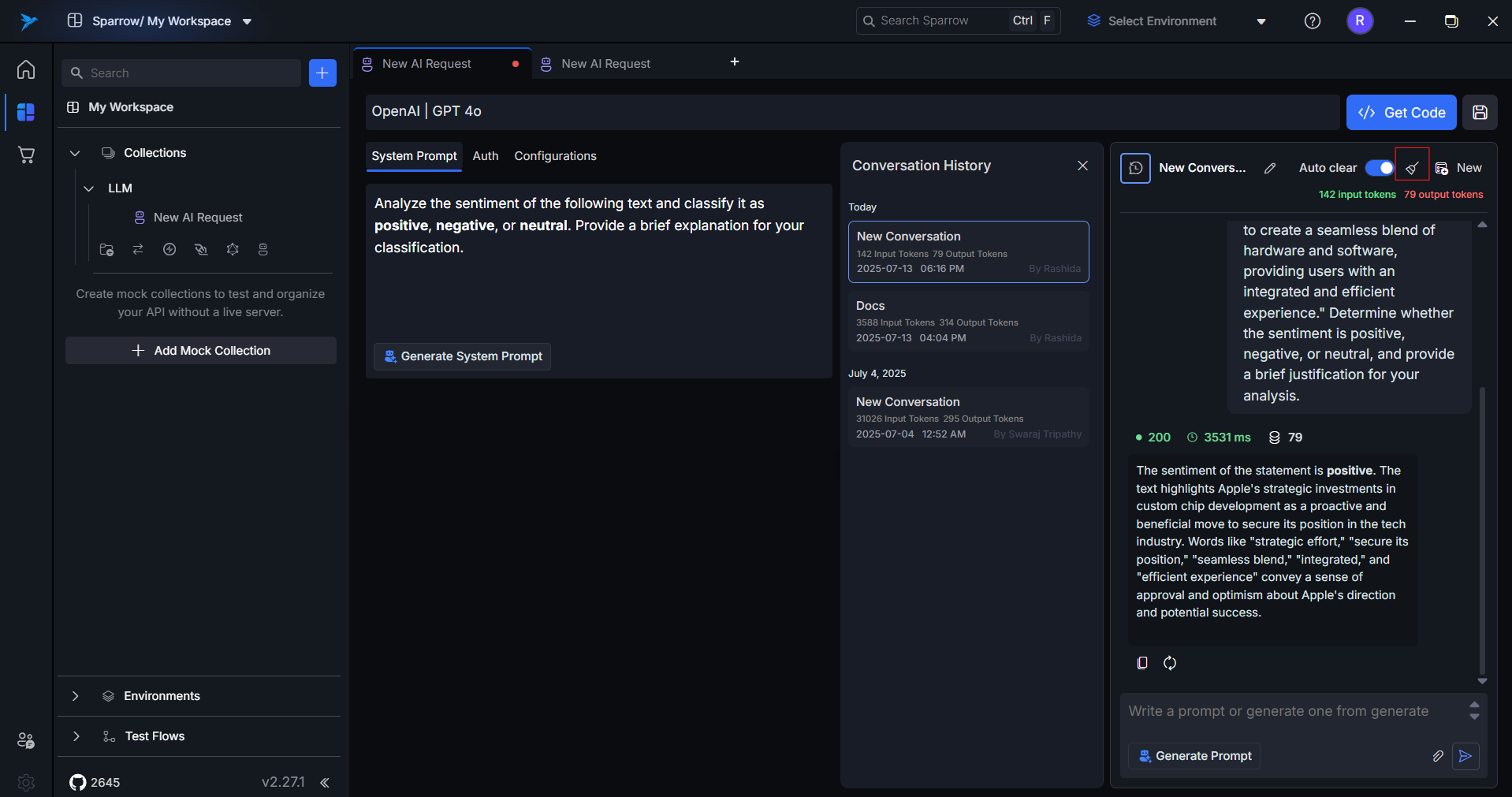
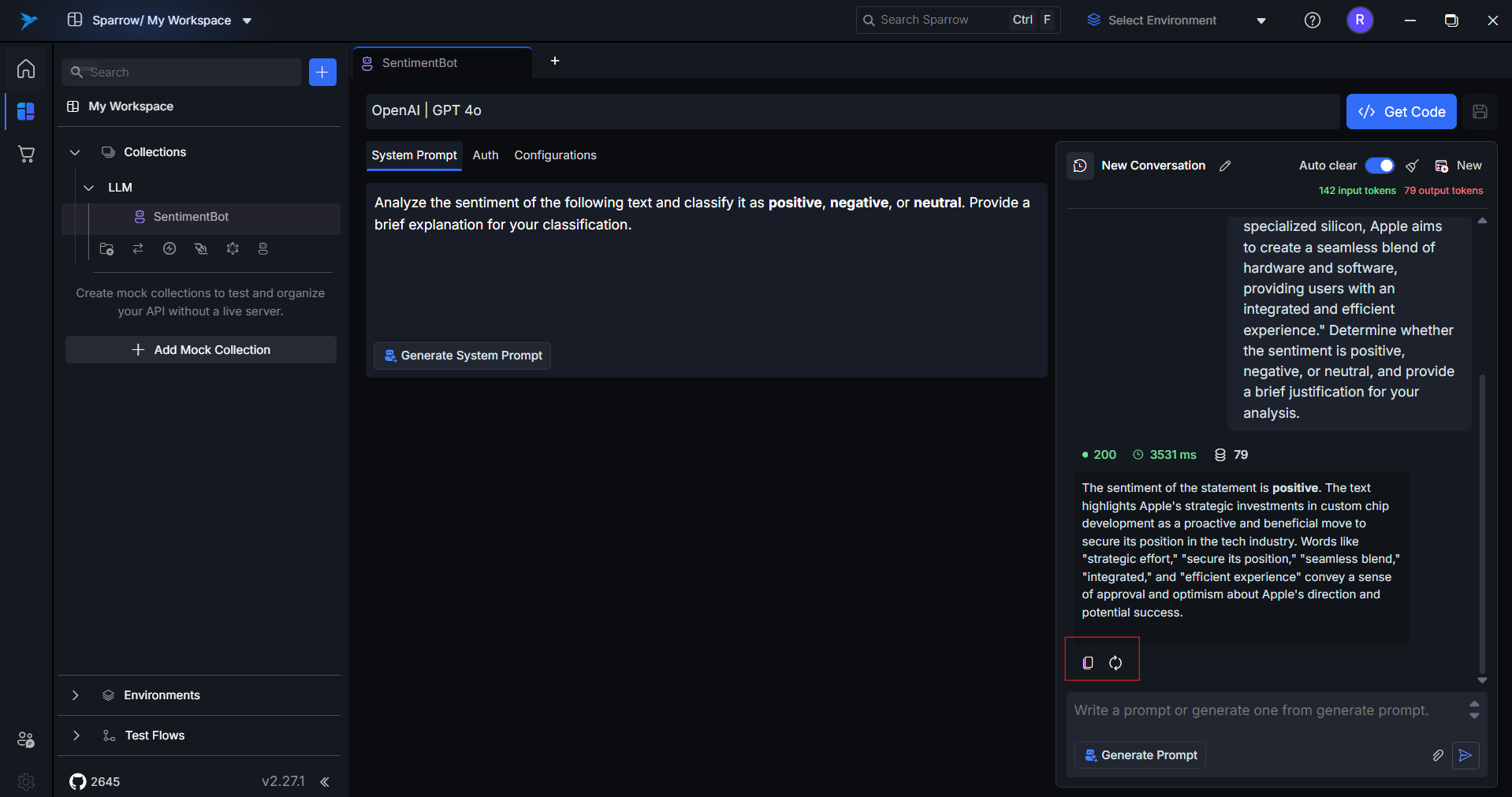
11. Copy or Regenerate Response
- Copy: Instantly copy the last model response.
- Regenerate: Resubmit the same prompt to get an alternate completion.
Ideal for comparing different variations or retrying failed outputs.
12. Token Counts and Response Time
After each response, Sparrow shows:
Input Tokens: Number of tokens used in your promptOutput Tokens: Tokens generated in the responseTotal Tokens: Combined usageResponse Time: Time taken by the model to respondResponse Status: Status codes - 2xx for successful run, 4xx for error cases
This is essential for cost tracking, usage management, and performance tuning — especially with token-based billing models.
Developer Tips
- Toggle Auto Clear OFF when testing multi-turn logic or assistant-style interactions.
- Use "Get Code" when moving from UI testing to integration.
- Use JSON output + structured system prompts for better extractability.
- Save well-performing prompt threads to collections.
- Monitor token usage to stay within limits on paid APIs.